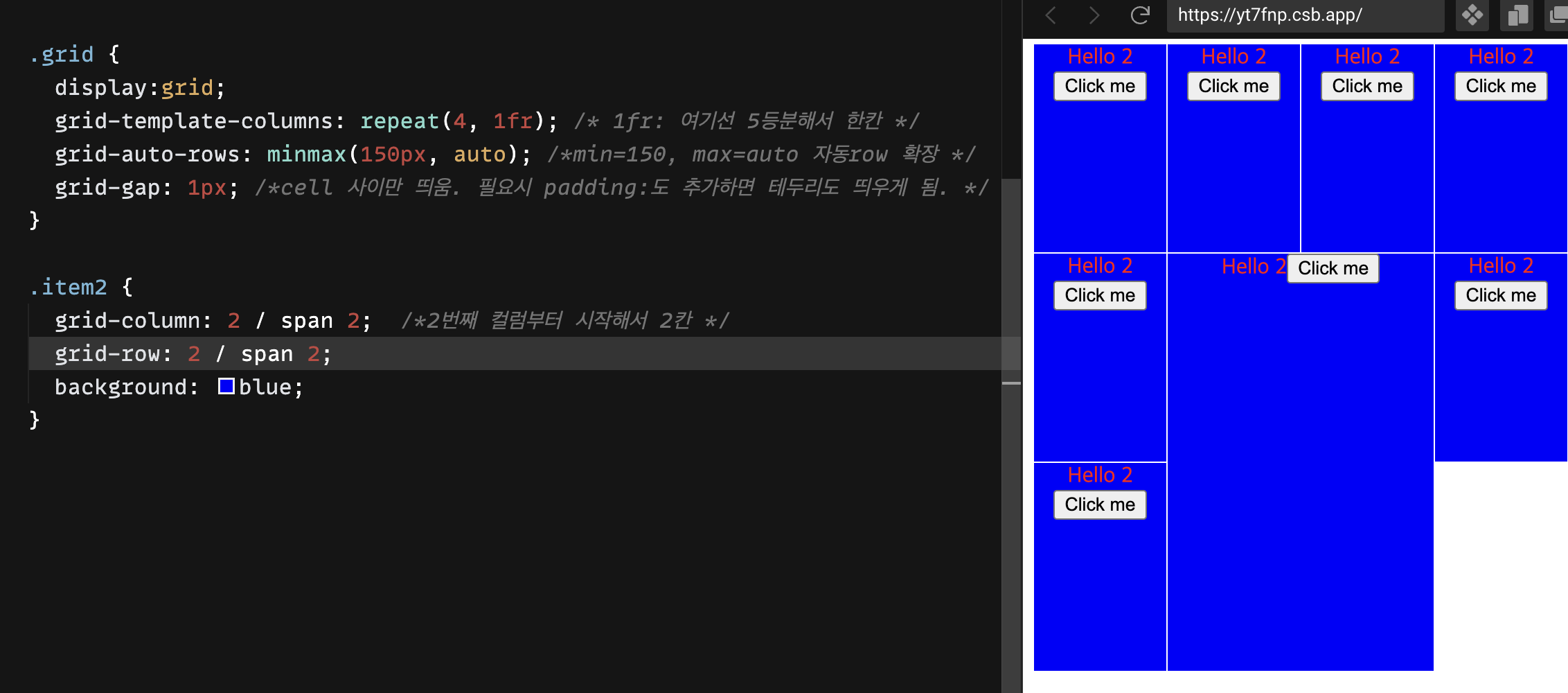
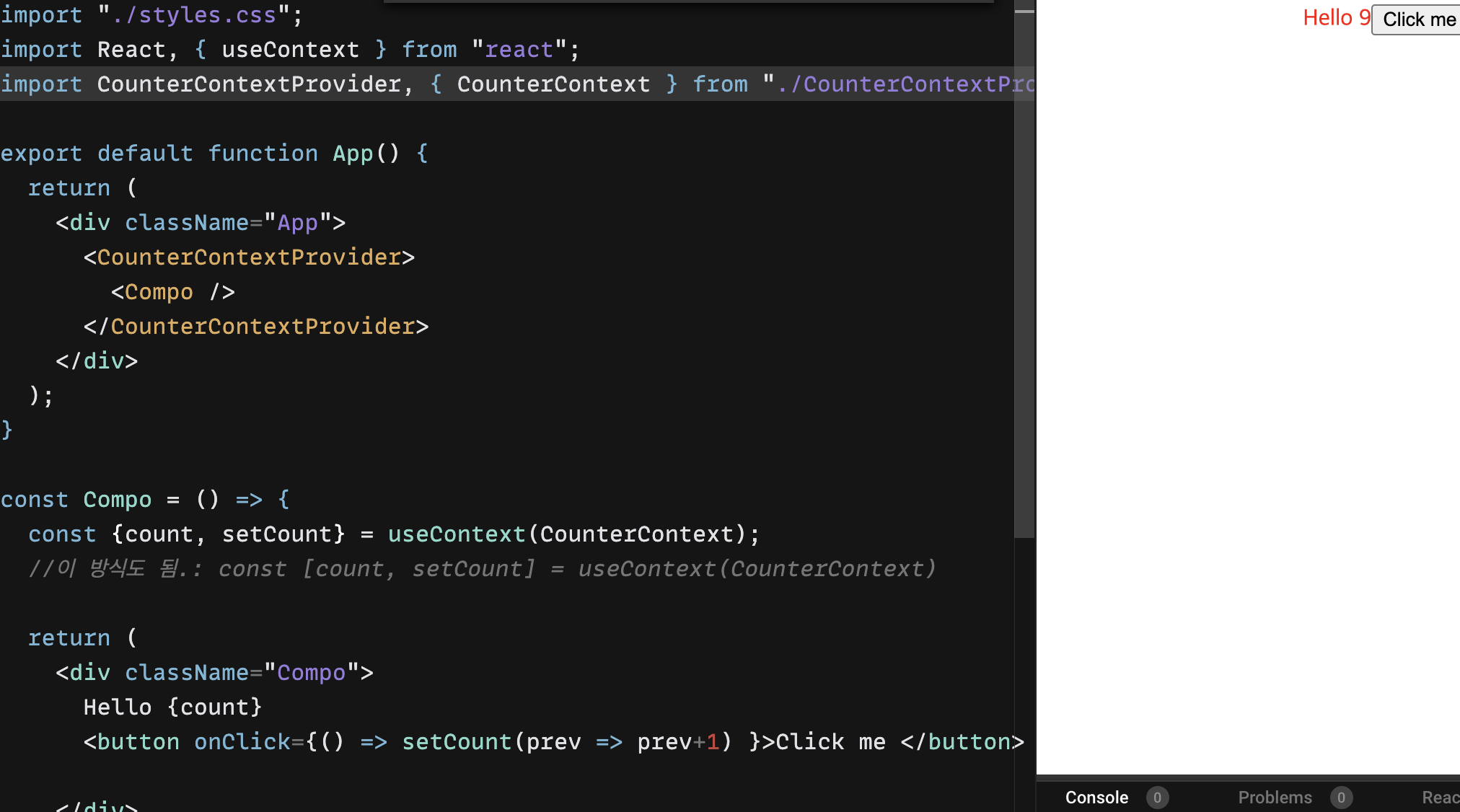
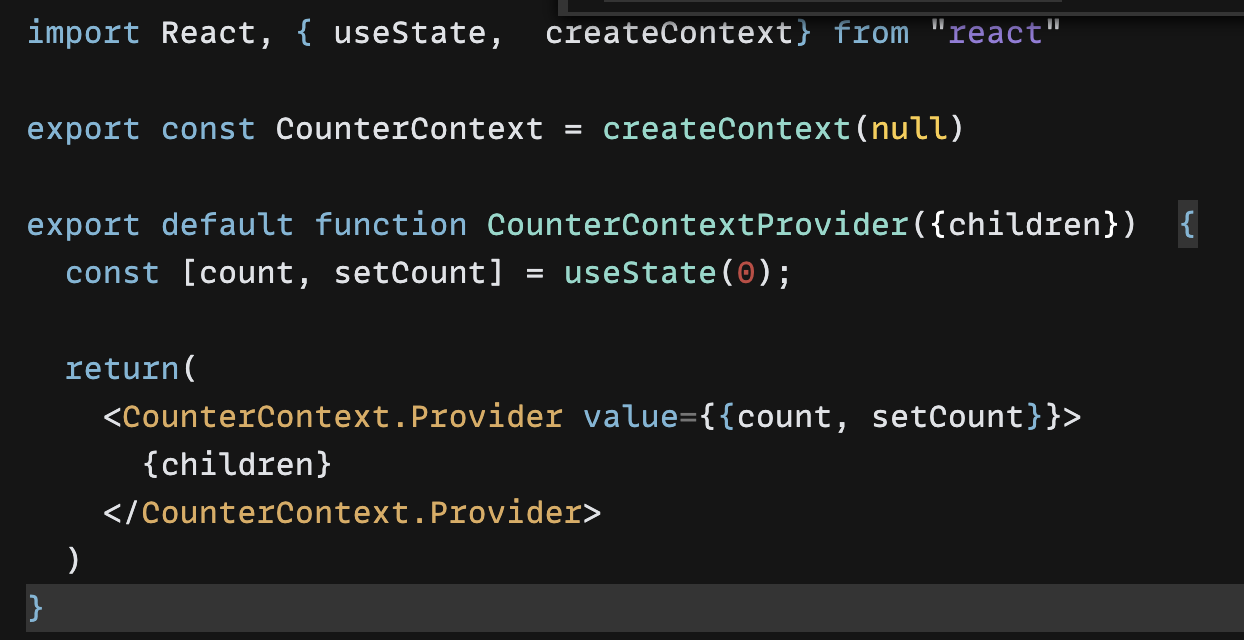
SSH 키를 생성하려면 터미널 또는 명령 프롬프트에서 다음 명령을 실행합니다:이 명령에서 "your_email@example.com" 부분을 본인의 이메일 주소로 바꿉니다. 키 생성 중에 암호를 설정하라는 메시지가 나오면 암호를 설정하세요. 암호는 SSH 키를 사용할 때 필요할 수 있습니다.
mathematicaCopy code
$ssh-keygen-ted25519-C"your_email@example.com"
키 생성이 완료되면, 공개 키를 GitHub에 추가해야 합니다. 터미널에서 다음 명령으로 공개 키를 복사합니다:
bashCopy code
$cat ~/.ssh/id_ed25519.pub
==> 공개키는 한 줄이며 ssh-ed25519 AAA로 시작하고 이메일로 끝납니다.
공개 키를 클립보드에 복사한 후, GitHub 계정 설정 페이지로 이동하여 "SSH and GPG keys" 섹션에 공개 키를 추가합니다.
리포지토리 Clone:
SSH 키가 GitHub에 등록되었으면, 해당 리포지토리를 clone할 수 있습니다. 터미널에서 다음 명령을 사용하여 리포지토리를 clone합니다:여기서 사용자명과 리포지토리명을 실제 사용자명과 리포지토리 이름으로 바꿉니다.
scssCopy code
$git clone git@github.com:사용자명/리포지토리명.git
만약 A PC에서 생성한 SSH 키를 B PC에서도 사용하려면, A PC에서 생성한 키를 B PC로 복사해야 합니다.
공개 키와 개인 키 복사 A PC의 SSH 키 파일을 B PC로 이동합니다. 예를 들어, 기본 경로(~/.ssh/id_ed25519와 ~/.ssh/id_ed25519.pub)를 복사합니다.
bash
코드 복사
# A PC에서 B PC로 복사 (B PC의 IP가 192.168.1.100이고 사용자명이 user라고 가정) scp ~/.ssh/id_ed25519* user@192.168.1.100:~/.ssh/
프런트로 Stream을 리턴하는 방식은 프런트 처리시 난이도가 높아서, 특수한 경우에 한해 사용하면 좋다.
1. Flux나 Observable 생성: WebFlux나 RxJava에서 Flux 또는 Observable을 사용하여 데이터 스트림을 생성합니다. 이 스트림은 비동기적으로 데이터를 생성하거나 가져올 수 있습니다. dependencies { implementation 'org.springframework.boot:spring-boot-starter-webflux' }
2. 예제코드 : 보통 Flux를 리턴하고 데이터가 1/0 개일경우는 Mono 리턴.
import reactor.core.publisher.Flux;
@RestController
public class StreamController {
@GetMapping(value = "/stream-data", produces = "text/event-stream")
public Flux<String> streamData() {
// 스트림 생성 예제 (여기서는 간단한 문자열 스트림)
return Flux.just("Data 1", "Data 2", "Data 3")
.delayElements(java.time.Duration.ofSeconds(1)); // 1초마다 데이터 전송
}
}
Vector 와 ArrayList의 차이 - Vector는 synchronized라서 Thred Safe하고 좀 늦다는 게 가장 큰 차이이고 - 둘 다 고정 사이즈이고 내부적으로는 array를 사용하며, size를 증가시킬 때 Vector는 100%씩 증가, ArrayList는 50%씩 증가.
소프트웨어 아키텍처 패턴은 시스템의 전반적인 구조를 설명합니다. 아키텍처 패턴은 시스템의 핵심 구조와 그 구조의 특징을 묘사하며, 대규모 설계 문제를 해결하기 위한 고수준의 템플릿입니다.
종류
계층형 패턴 (Layered Pattern): 시스템을 독립된 계층으로 나누고 각 계층간의 상호작용을 정의합니다. Presentation Layer, Application Layer, Domain Layer(비즈니스 로직), Infra Layer(데이터베이스 상호작용)
클라이언트-서버 패턴: 클라이언트와 서버의 역할 분리로 서비스 요청과 처리를 관리합니다.
MVC (Model-View-Controller) 패턴: 사용자 인터페이스와 비즈니스 로직을 분리하여 관리합니다. View(사용자 상호작용) -> Controller에서 Model(비지니스 로직)과 View사이의 중계자 역할을 하게 됨.
이벤트 버스 패턴: 컴포넌트 간 메시지를 중앙 이벤트 버스를 통해 전달합니다.
마이크로서비스 패턴: 작은 서비스로 분할하여 독립적으로 운영 및 개발할 수 있게 합니다. 그 외 6~10번 더 나열하자면... (Master-slave pattern . Pipe-filter pattern - 파이프를 통해 흐르는 데이터를 중간중간 필터 모듈이 처리하는 패턴. . Broker pattern . Peer-to-peer pattern . Blackboard pattern - "블랙보드"에 비유되는 중앙 저장소에 데이터를 공유 . (interpreter패턴도 여기 들어갈 수 있는데, 아래꺼랑 헤깔려서 일단 제외)
SW 디자인 패턴
정의
디자인 패턴은 소프트웨어 설계 단계에서 특정 문제를 해결하는 일반적인 해법을 제공합니다. 디자인 패턴은 보다 구체적이며, 작은 범위의 설계 문제에 적용됩니다.
종류
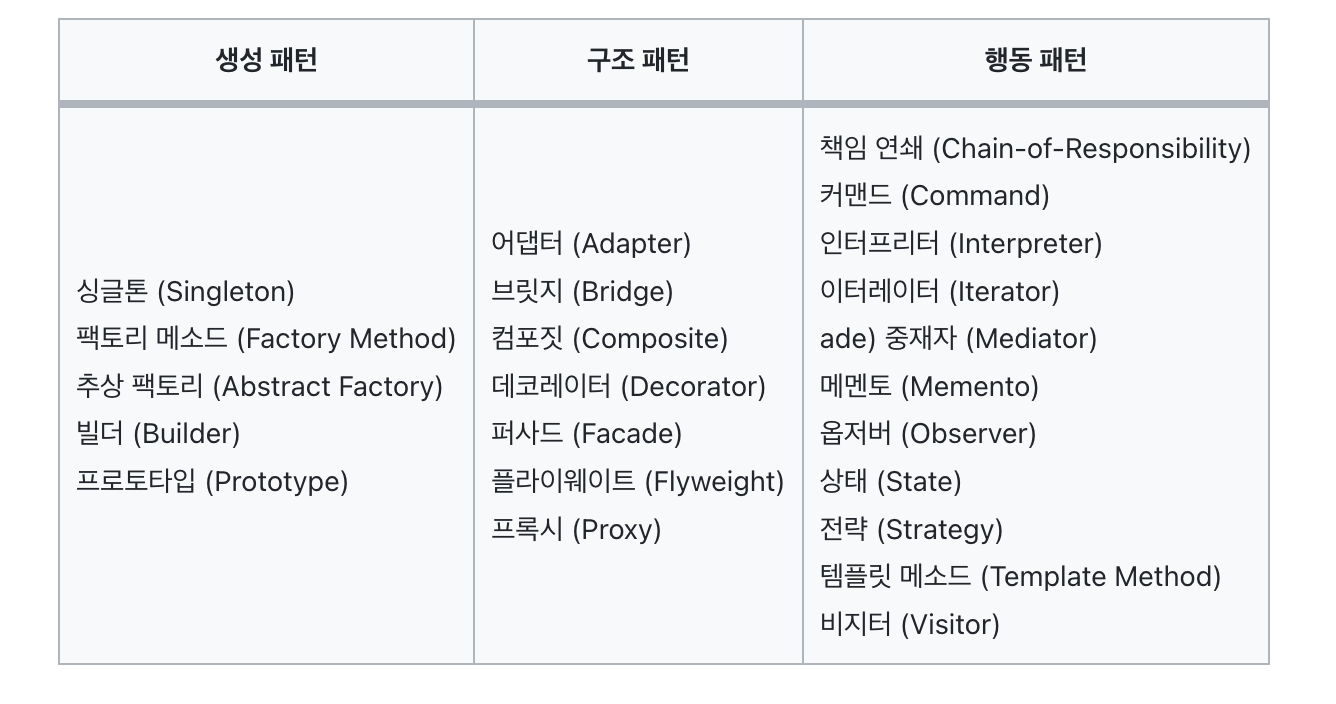
생성 패턴: 객체 생성과 관련된 패턴으로, 싱글턴, 팩토리 메서드, 추상 팩토리, 빌더, 프로토타입 등이 있습니다.
구조 패턴: 객체 간의 구조화된 관계를 설명하는 패턴으로, 어댑터, 브리지, 컴퍼지트, 데코레이터, 퍼사드, 플라이웨이트, 프록시 등이 있습니다.
행동 패턴: 객체 간의 상호작용과 책임을 다루는 패턴으로, 책임 연쇄, 명령, 해석자, 반복자, 중재자, 메멘토, 옵저버, 상태, 전략, 템플릿 메서드, 방문자 등이 있습니다.
- C.A.P 이론 : CAP 이론은분산 시스템에서 세 가지 핵심C.A.P 중 어느 두 가지만을 선택할 수 있다는 개념을 나타내는 이론입니다. 이런 선택은 분산 시스템의 설계와 운영에서 중요한 결정을 내리는 데 영향을 미칩니다.
일관성(Consistency): 모든 노드가 동시에 같은 데이터를 보는 것입니다. 즉, 어떤 노드가 데이터를 변경하면, 다른 모든 노드도 동일한 데이터를 볼 수 있어야 합니다.
가용성(Availability): 모든 요청은 성공하거나 실패해야 합니다. 시스템은 항상 요청에 대한 응답을 주어야 합니다. 실패한 노드에 대한 요청도 응답을 반환해야 합니다.
분할 내성(Partition Tolerance): 네트워크 지역이 분할되고 지역간 통신 실패 같은 상황에서도 시스템이 정상적으로 작동하거나 복구할 수 있어야 함 => Consistency와 바로 상반 됨.
CAP 이론은 "일관성", "가용성", "분할 내성"을 모두 동시에 만족시키는 것은 불가능하다고 주장합니다. 이를 그림으로 나타내면 CAP 이론의 유명한 "CAP 삼각형"이 나옵니다. 이 삼각형에서는 세 속성이 모두 연결되어 있는데, 그 중에서 두 개를 선택할 수 있다는 것을 의미합니다.
CAP 이론은 분산 시스템의 설계와 구축 시 어떤 속성을 우선시할 것인지 결정해야 한다는 중요한 이론
- SDLC (S/w Development LIFE Cycle) : 개발을 위한 단계별 접근방식 - Waterfall, agile, V-Model 등이 있다. REF - SRS (Service Requirement Specification) - 요구사항 정의 느낌.
- SLE (Service Level ObjEctive)의 약자로, 서비스 수준 목표를 나타내는 개념입니다. SLE는 서비스의 성능 및 가용성과 같은 품질 지표를 정의하고 측정하기 위해 사용. 즉: 응답시간, 가용성, 에러비율, 처리량 등.
1. 요구사항 명확화 : 핵심기능 , 트래픽이나 유저수 등 확인. (1초에 1000요청, 유저 100만명에 서버 기본2대+1씩, 1명당 하루 86.4건 요청)
(High Level Design)
2.1 API - High Level Design (Rest API)
2.2 Component - High Level Design : 로드 밸런스 + VM 몇대(x 오토스케일링) + DB 단 - 프론트를 SPA방식으로, 웹서버 없이 대신에 글로벌서비스의 경우 CDN이나, 로컬서비스면 S3같은 object storage로 미디어 부하분리. (VM이냐 컨테이너 기반이냐는 조직이 크고 여러 팀으로 나누어 개발한다면 독립배포가 중요해져서 컨테이너 기반이 좋을 것 같고.. 조직이 작으면 VM기반이 좋을 것 같음)
2.3 DB선택 : 복제냐 샤딩이냐, A:카산드라/실리아. B. dynamoDB. C. mongoDB/documentDB. 4. RDB => 옵션중에 트래픽이 많거나 많아질 확률이 있고 필드간의 관계도 좀 필요하다면 B/C 중에 선택! (전반적으로 B/C가 샤딩등 분산환경에 유리하다. RDB보다는 개발리소스도 좀 적게 들고..) B/C의 차이는 C가 좀 더 index등의 튜징여지가 있으므로 엔지니어 구성에 따라 선택가능) => 향후 MSA를 대비해 foreign키 없게 하고, Join을 최소화해서 분리가 용이하도록!
3. DB 테이블 설계
4.(여유가 되면) Fault tolerance 고려
DB - 용량에서 1. master/slave구조, 2. 샤딩/ Table파티셔닝 고민필요. (index 는 application영역이라 보고 일단 제외) =>샤드키는 Cardinality가 높은 값으로 선정. ( RDB - postgreSQL만 슈평분할(샤딩과 유사)지원, mySQL/oracle은 테이블파티셔닝만 지원 NoSQL - mongoDB, cansandra 등이 샤딩 지원 : 샤딩시 DB가 빨라지지만 aggregation등에선 늦어질 수도 있음)
master/slave구조: 오라클에선 replication이라고 부르며 transaction replication 방식이 일반적)
////// MSA로 전환 전 고려사항//////
1. API Gateway 는 수직 방향 서비스 메시는 수평 방향으로 라우팅/로드밸런싱 등을 수행한다.
2. DB 트랜잭션을 A. 동기화 형태로 홀딩하면서 API호출 완료 후 트랜잭션 수행 : 초기에 일반적 방식. B. 분산트랜잭션(즉 2단계 커밋, 표시나 lock을 하고 API호출 후 완료.)으로 할것인지, C. 이벤트 기반으로 LLT(long live Transaction)이용하는 사가패턴을 적용하고 실패시 보상트랜잭션을 개발할 건지 고민필요.
=> 사가패턴도 2가지가 있는데 중앙관리형과 서비스별 자체 관리형이 있다.
//////////// MSA 장단점
MSA의 핵심은 1. 데이터 분리와 2. API Gateway 라고 생각한다. (단, 1. 데이터 분리가 난이도가 높기 때문에, 운영중인 모노리스를 MSA로 변환해야하는 실상황에서는 서비스만 먼저 분리하고 나중에 데이터를 분리하는 방법이 현실적이다)
모노리스 장단점:
(장점) 배포 및 테스트도 하나의 애플리케이션만 수행하면 되기 때문에 개발 및 환경설정이 간단, 운영 관리가 용이,
(단점들 : 시스템이 커지기 시작하면 등장) - 빌드/테스트 시간이 길어진다. 작은 수정에도 시스템 전체를 빌드해야 하며, 테스트 시간도 길어진다. 요즘처럼 CI/CD가 강조되는 시점에서는 큰 문제가 될 수 있다. - 하나의 서비스가 모든 서비스에 영향을 준다. 이벤트 서비스에 트래픽이 몰려 해당 서버가 죽게 된다면 다른 모든 서비스 역시 마비 되는 상황이 오게 됩니다 - 선택적 확장이 불가능 이벤트로 인해 서비스 접속 량이 폭증할 경우 프로젝트 전체를 확장해야만 한다.
MSA 장단점:
(장점) 1. 서비스별 독립된 배포, 2. 해당 서비스별 확정.
(단점들) 모노리틱 아키텍처는 서비스간의 호출이 하나의 프로세스 내에서 이루어지기 때문에 속도가 빠르지만, MSA의 경우 서비스간 호출을 API통신을 이용하기 때문에 속도가 느리다.
OpenID Connect (OIDC)는 OAuth 2.0을 기반으로 한 인증 프로토콜로, JWT (JSON Web Tokens)를 사용하여 사용자 정보를 안전하게 전달합니다. OIDC에서 생성되는 JWT는 특히 'ID 토큰'이라고 불립니다.
ID 토큰에는 아래와 같은 클레임들이 포함될 수 있습니다:
iss: 토큰을 발행한 주체(Issuer)를 나타냅니다.
sub: 주체(Subject)를 나타냅니다. 이는 고유한 식별자로, 토큰 발행자가 관리하는 사용자의 ID입니다.
aud: 수신자(Audience)를 나타냅니다. 이 클레임은 이 토큰이 의도된 수신자 또는 수신자들의 목록입니다.
exp: 만료 시간(Expiration Time)을 나타냅니다. 이 시간 이후에는 토큰이 더 이상 유효하지 않습니다.
iat: 토큰이 발행된 시간(Issued At Time)을 나타냅니다.
FACEBOOK 을 이용한 로그인시.
iss: 이 클레임은 토큰을 발행한 주체(Issuer)를 나타냅니다. 이 경우에는 Facebook이 될 것입니다. 일반적으로, Facebook에서 발행한 토큰의 'iss' 값은 'https://facebook.com'과 같은 형태로 되어있습니다.
sub: 이 클레임은 주체(Subject)를 나타냅니다. 이는 토큰 발행자가 관리하는 사용자의 고유 식별자입니다. Facebook을 통해 인증을 받은 경우, 'sub' 클레임은 Facebook에서 사용자에게 할당한 고유 ID입니다.
aud: 이 클레임은 수신자(Audience)를 나타냅니다. 이는 해당 토큰이 의도된 수신자입니다. 즉, 특정 e-commerce 서비스의 식별자가 될 것입니다. 이 서비스가 Facebook에 등록되었다면, Facebook은 이 서비스의 'client_id'를 'aud' 클레임에 넣어 ID 토큰을 생성합니다. 그런 다음, 이 토큰이 e-commerce 서비스에 전달되어, 이 서비스는 'aud' 클레임을 검사하여 토큰이 자신에게 보내진 것임을 확인할 수 있습니다.
Object oriented 디자인 패턴
객체 지향 디자인 패턴(Object-Oriented Design Patterns)은 소프트웨어 개발에서 반복적으로 발생하는 문제들을 해결하기 위해 공통된 설계 방법을 제공하는 패턴들의 집합입니다. 이러한 패턴들은 객체 지향 프로그래밍에서 유용하게 사용될 수 있으며, 코드의 재사용성, 유지보수성, 확장성 등을 향상시킬 수 있습니다. 여기서는 몇 가지 대표적인 객체 지향 디자인 패턴에 대해 설명하겠습니다.
Singleton Pattern (싱글턴 패턴): 이 패턴은 오직 하나의 인스턴스만 생성하고, 그 인스턴스에 접근할 수 있는 전역적인 접근점을 제공합니다. 주로 리소스를 공유하거나 설정 정보와 같은 단일 객체를 공유해야 할 때 사용됩니다.
Factory Pattern (팩토리 패턴): 객체의 생성을 처리하는 패턴으로, 객체를 생성하기 위한 인터페이스를 정의하고, 서브 클래스에서 어떤 클래스의 인스턴스를 생성할지를 결정합니다. 이를 통해 객체 생성 코드를 클라이언트로부터 분리시킬 수 있습니다.
Observer Pattern (옵저버 패턴): 이벤트 발생 시 관찰자(옵저버)들에게 자동으로 알림을 보내는 패턴입니다. 주로 한 객체의 상태 변화에 따라 다른 객체들이 업데이트되어야 하는 상황에서 사용됩니다.
Strategy Pattern (전략 패턴): 알고리즘을 정의하고, 이를 사용하는 클라이언트와 분리시키는 패턴입니다. 각각의 알고리즘을 캡슐화하고, 런타임 시에 알고리즘을 변경할 수 있습니다.
Decorator Pattern (데코레이터 패턴): 객체의 기능을 동적으로 확장하기 위해 사용되는 패턴입니다. 기존 객체를 감싸는 데코레이터 클래스를 생성하여, 새로운 동작을 추가하거나 변경된 동작을 제공합니다.
Proxy Pattern (프록시 패턴): 실제 객체에 대한 대리자(Proxy)를 제공하는 패턴으로, 클라이언트와 실제 객체 사이에 중간 계층을 두어 추가적인 기능을 제공하거나 접근을 제어할 수 있습니다.
Template Method Pattern (템플릿 메서드 패턴): 알고리즘의 구조
Scanner sc = new Scanner(System.in);
String s = sc.nextLine();
첫번재 n을 숫자로 읽고 라인 쭉 읽는 방법.
int n=sc.nextInt();
String []s=new String[n+2];
for(int i=0;i<n;i++){
s[i]=sc.next();
}
기존 방식.
try {
BufferedReader br=new BufferedReader(new InputStreamReader(System.in));
int k = 5;
List<Integer> ret = new ArrayList<>();
while ( k-- > 0) {
String st = br.readLine();
}